
 Back
Back

The Physical AI Era Begins
The Physical AI Era Begins
From seeing to foreseeing. Autonomous driving is where Physical AI scales first.
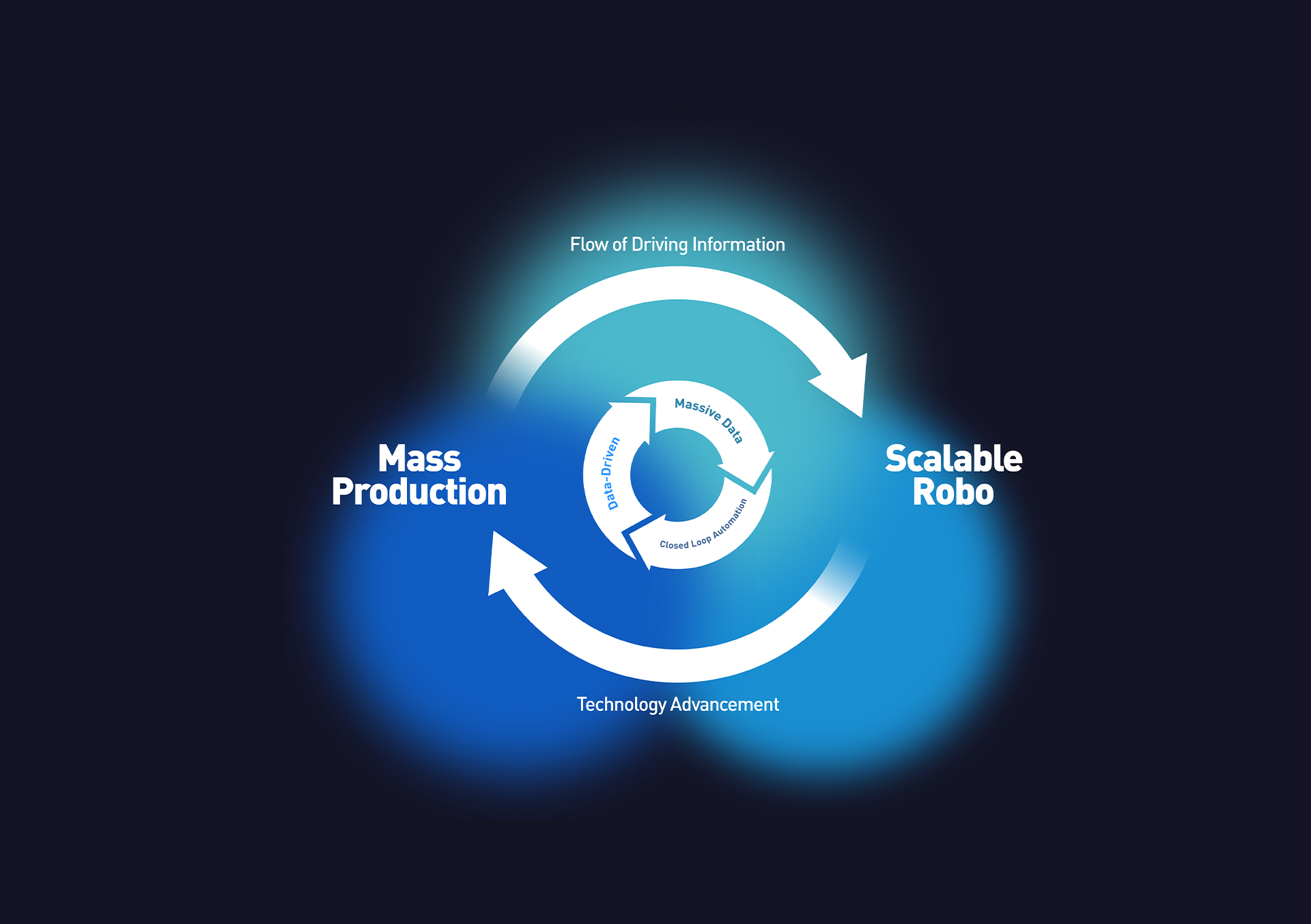
Driven by the data flywheel and built on the World Model, Momenta advances two tracks in parallel – Mass Production and Scalable Robo – bringing Physical AI from concept to everyday life.
From seeing to foreseeing. Autonomous driving is where Physical AI scales first. Driven by the data flywheel and built on the World Model, Momenta advances two tracks in parallel – Mass Production and Scalable Robo – bringing Physical AI from concept to everyday life.
-













Mass Production
Our mass production solutions cover the full spectrum of assisted driving (AD) features from L2 to L2++, with future advancements planned for L3 and L4. These solutions, are adaptable across different vehicle models and meet the diverse needs of various market segments.
-





Scalable Robo
Momenta is committed to scalable autonomous driving solutions, currently centered on Robotaxi and Robovan, while continuously expanding into Robotruck for more commercial scenarios.

